Transformer Sentence Embeddings¶
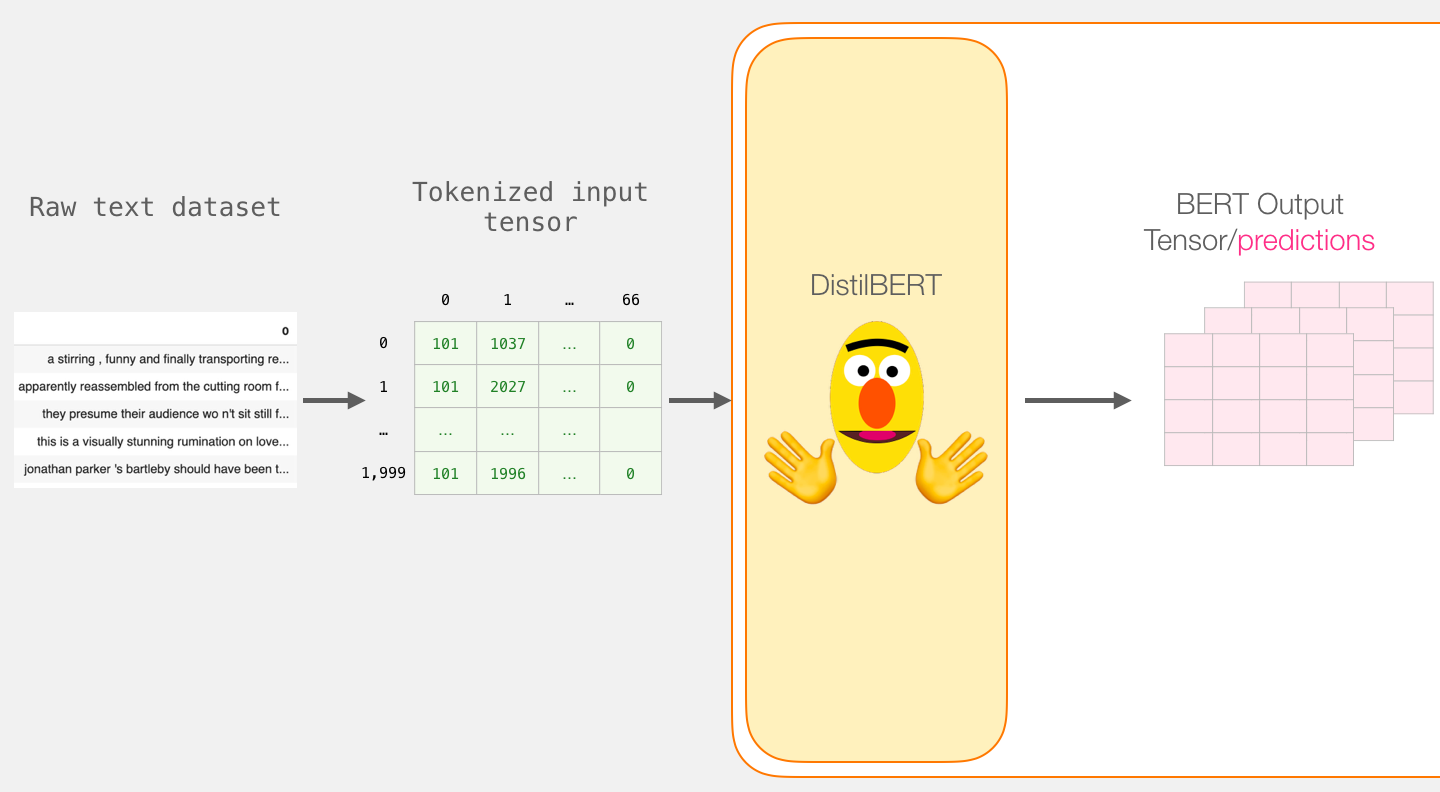
First we create sentence embeddings for each utterance. We use a pretrained DistilBert model to obtain contextual word embeddings and then concatenate the CLS token embedding and the mean of the last layer. Note that in order to feed batches into out model we need to temporarily flatten our input_ids, i.e. we get three times as many input sentences as the specified batch_size.
For more information on the (Distil)Bert models one can look at Jay Alammar's blog posts (A Visual Guide to Using BERT for the First Time and The Illustrated BERT, ELMo, and co.) where also the following illustration is taken from.
Further references:
To illustrate the model let us import our dataloader.
path = 'data/clean_train.txt'
batch_size = 5
max_seq_len = 10
emo_dict = {'others': 0, 'sad': 1, 'angry': 2, 'happy': 3}
loader = dataloader(path, max_seq_len, batch_size, emo_dict)
input_ids, attention_mask, labels = next(iter(loader))
The DistilBert model outputs
- 768-dimensional embeddings for each of the 'max_seq_len' tokens and each of the three utterances of the
batch_sizeconversations and - a list of the hidden-states in all of the 6 DistilBert transformer layers (including the first embedding)
embeds_model = sentence_embeds_model()
last_layer, hidden_states = embeds_model.transformer(input_ids = input_ids.flatten(end_dim = 1), attention_mask = attention_mask.flatten(end_dim = 1))
input_embeds = embeds_model.transformer.embeddings(input_ids.flatten(end_dim = 1))
assert torch.all(hidden_states[0] == input_embeds)
assert torch.all(hidden_states[-1] == last_layer)
len(hidden_states), last_layer.shape
Let us now create sentence embeddings (we put the model in evaluation mode to deactivate dropout for later consistency checks). Note that the forward method of the model reshapes the output again back to the shape of the corresponding input_ids.
embeds_model.eval()
assert(embeds_model.transformer.transformer.layer[0].dropout.training == False)
sentence_embeds = embeds_model(input_ids = input_ids, attention_mask = attention_mask)
assert input_ids.shape[:2] == sentence_embeds.shape[:2]
assert sentence_embeds.shape[-1] == embeds_model.embedding_size
input_ids.shape, sentence_embeds.shape
We also check if the layerwise_lr method outputs all model parameters.
count = 0
for group in embeds_model.layerwise_lr(2.0e-5,0.95):
count += len(list(group['params']))
assert count == len(list(embeds_model.parameters()))
Context Transformer and Classification¶
Next we use another transformer model to create contextual sentence embeddings, i.e. we model that a conversation consists of three utterances. This is partly motivated by the BERTSUM paper.
Moreover, we add a classification model for the emotion of the last utterance where we augment the loss by a binary loss due to the unbalanced data.
Note that for our convenience we use
- a linear projection of the sentence embeddings to a given
projection_size - a (not pre-trained) DistilBertForSequenceClassification and flip the order of the utterances as the first input embedding gets classified by default
- only one attention head, see also the paper Are Sixteen Heads Really Better than One?.
Let us initiate a the context_classifier_model with the corresponding projection_size of the sentence embedding model
projection_size = 100
n_layers = 2
classifier = context_classifier_model(embeds_model.embedding_size, projection_size, n_layers, emo_dict)
and do some basic checks.
classifier.eval()
assert(classifier.context_transformer.distilbert.transformer.layer[0].dropout.training == False)
loss, logits = classifier(sentence_embeds, labels = labels)
assert torch.all(logits == classifier(sentence_embeds))
assert loss == torch.nn.CrossEntropyLoss()(logits, labels) + classifier.bin_loss(logits, labels)
loss, logits
Finally, for our main consistency check we compute the gradient of the loss w.r.t. to the input embeddings.
input_embeds = input_embeds.clone().detach().requires_grad_(True)
sentence_embeds_check = embeds_model(input_embeds = input_embeds, attention_mask = attention_mask)
logits_check = classifier(sentence_embeds_check)
assert torch.all(logits == logits_check)
logits_check[1,0].backward()
input_embeds.grad[:,0,0]
As anticipated, we see that only the fourth, fifth, and sixth input embedding effect the second prediction. These correspond to the second conversation:
assert torch.all(input_embeds[3:6] == embeds_model.transformer.embeddings(input_ids[1]))
Metrics¶
Lastly, we define the metrics, i.e. microaveraged precision, recall, and f1-score (ignoring the others class), for the evaluation of our model according to the SemEval-2019 Task 3 challenge.
metric = metrics(loss, logits, labels)
metric
f1_score(metric['tp'], metric['fp'], metric['fn'])